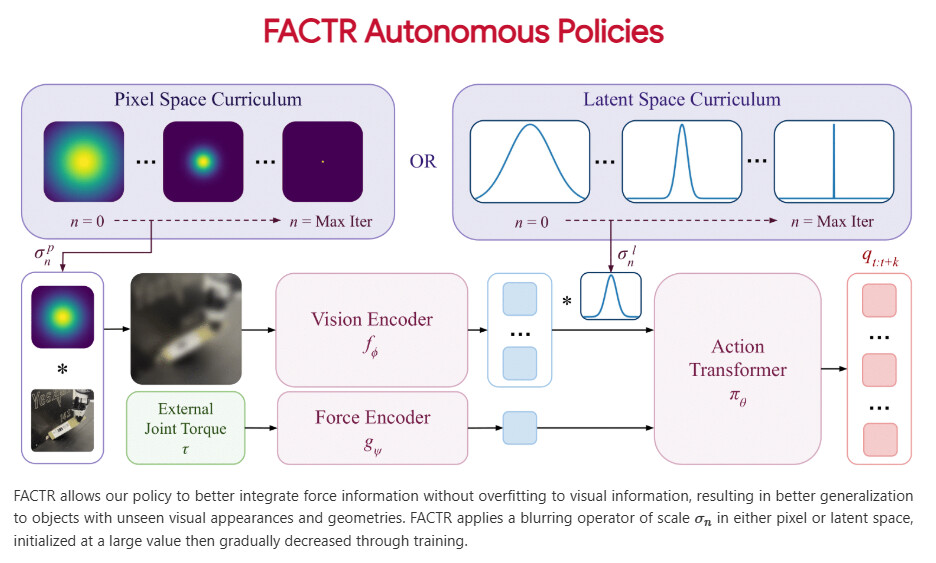
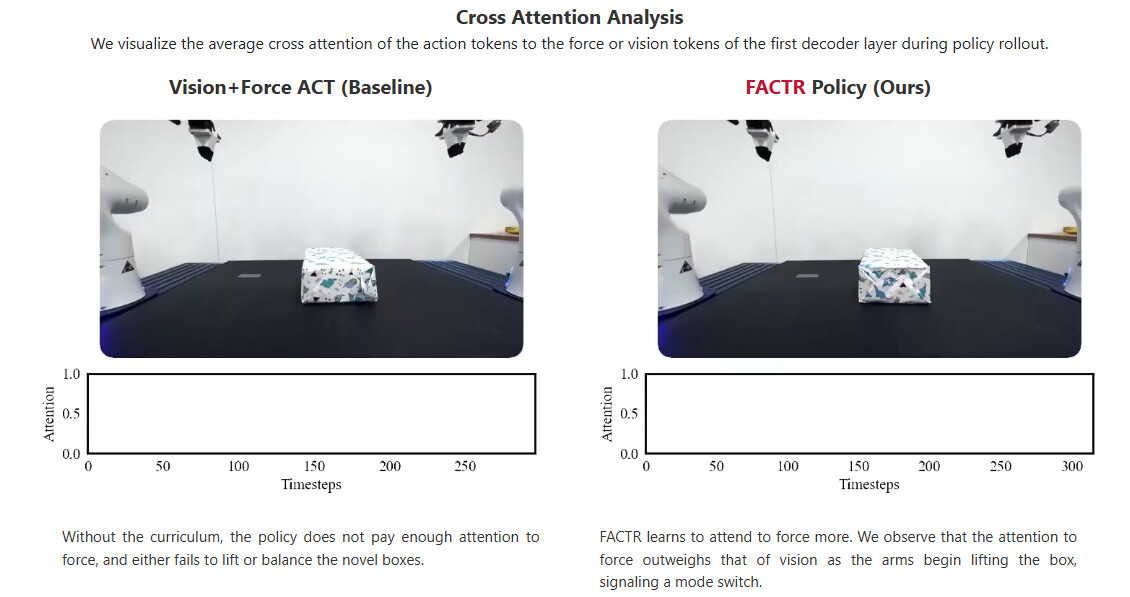
Abstract: Many contact-rich tasks humans perform, such as box pickup or rolling dough, rely on force feedback for reliable execution. However, this force information, which is readily available in most robot arms, is not commonly used in teleoperation and policy learning. Consequently, robot behavior is often limited to quasi-static kinematic tasks that do not require intricate force-feedback. In this paper, we first present a low-cost, intuitive, bilateral teleoperation setup that relays external forces of the follower arm back to the teacher arm, facilitating data collection for complex, contact-rich tasks. We then introduce FACTR, a policy learning method that employs a curriculum which corrupts the visual input with decreasing intensity throughout training. The curriculum prevents our transformer-based policy from over-fitting to the visual input and guides the policy to properly attend to the force modality. We demonstrate that by fully utilizing the force information, our method significantly improves generalization to unseen objects by 43% compared to baseline approaches without a curriculum.



Full Project Page: FACTR: Force-Attending Curriculum Training for Contact-Rich Policy Learning
All Credits Go To: Jason Jingzhou Liu, Yulong Li, Kenneth Shaw, Tony Tao, Ruslan Salakhutdinov, Deepak Pathak, and Carnegie Mellon University
Other Acknowledgements: Arthur Allshire, Andrew Wang, Mohan Kumar Srirama, Ritvik Singh for discussions about the paper. We also thank Tiffany Tse, Ray Liu, Sri Anumakonda, and Sheqi Zhang with teleoperation. This work is supported in part by ONR MURI N00014-22-1-2773, ONR MURI N00014-24-1-2748 and AFOSR FA9550-23-1-0747.